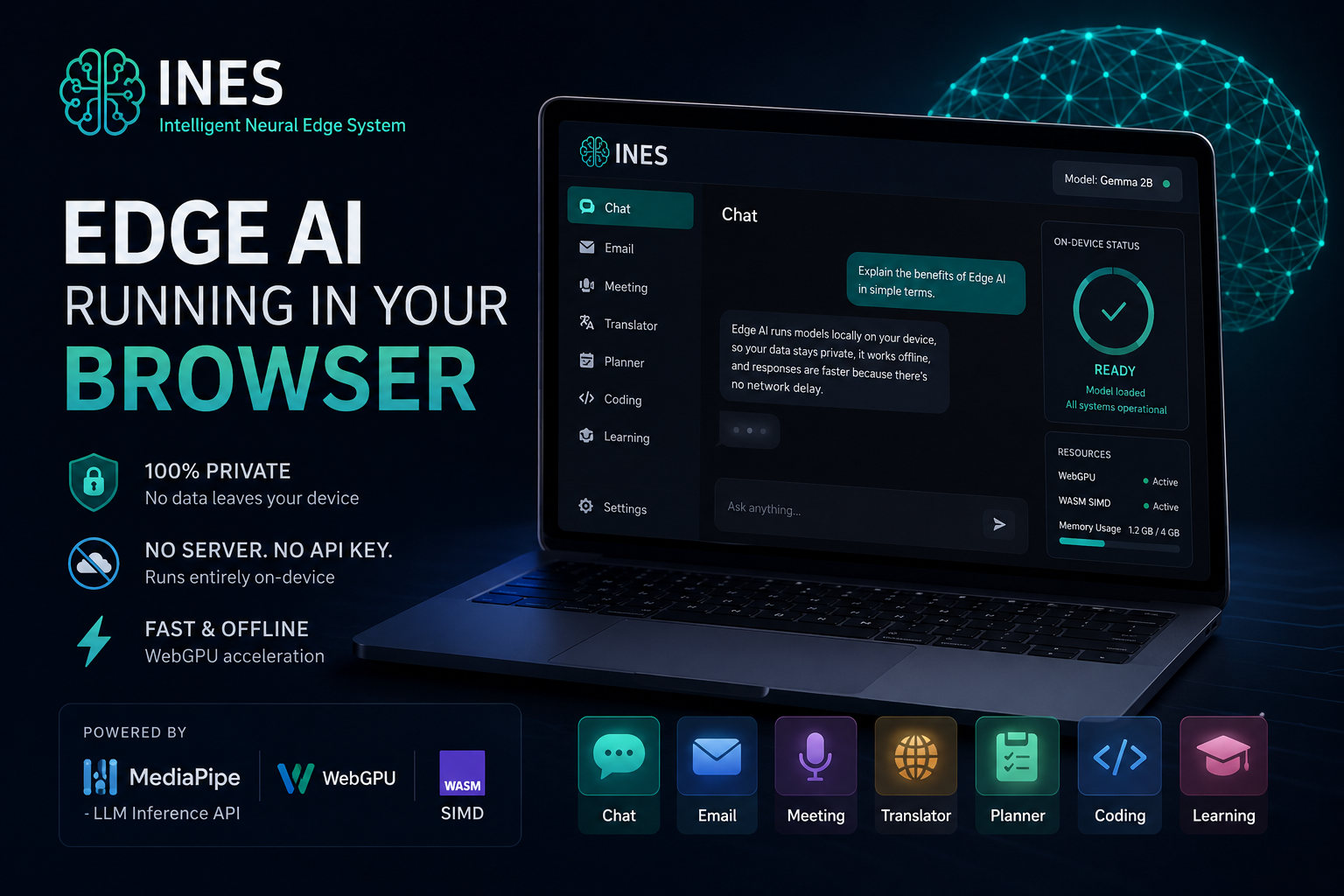
🚀 Edge AI running in your browser
Think about Language Model as “cloud-only” systems: APIs, servers, tokens, latency, privacy trade-offs.
But what if none of that was necessary?
I built INES - Intelligent Neural Edge System, a full Small Language Model, SLM-powered application that runs entirely inside the browser.
- No server.
- No API key.
- No data leaving your device.
🧠 What makes INES different?
INES runs a SML like Gemma model directly on-device using:
- Google’s MediaPipe LLM Inference API
- WebGPU acceleration
- WASM SIMD fallback when needed
The model is loaded once as a binary file and then everything happens locally in the tab.
After that moment → the browser becomes the AI runtime.
⚙️ One model → five AI systems
A single LlmInference instance powers five specialized tools:
- 💬 Chat → multi-turn assistant
- ✉️ Email → rewrite, summarize, adjust tone
- 🎙️ Meeting → speech → transcript → structured decisions
- 🌍 Translator → offline, auto-detect, 10 languages
- ✅ Planner → AI-generated daily task system
- 👨💻 Coding → code generation + preview sandbox
- 💬 Learning → Learning
Each tab injects its own system prompt — effectively turning one model into multiple agents.
🔒 Privacy by design (not policy)
- Prompts never leave the device
- Meeting audio processed locally
- Todo lists stored in
localStorage - No analytics, no telemetry, no accounts
This is what “local-first AI” actually looks like in practice.
⚡ Why Edge AI matters
This architecture enables use cases that cloud AI struggles with:
- 🔐 Corporate environments with strict data policies
- 🌐 Offline or air-gapped systems
- 📶 Low-connectivity regions
- 🧪 Educational and demo environments
- 🧍 Privacy-first personal tools
Edge AI isn’t just about performance - it’s about control shifting back to the user.
🧩 The technical reality
Running an SLM in-browser is not trivial:
- WebGPU vs WASM fallback paths
- Model loading as
ArrayBuffer(not blob URLs) - Single shared inference runtime across UI modules
- Streaming token generation in real time
- Prompt orchestration per feature (chat/email/meeting/etc.)
But the result is simple:
A complete AI workstation that runs inside a single HTML/SPA client.
🔗 Project
GitHub: https://github.com/marcomattolab/ines
Built with:
- Angular with PWA
- MediaPipe GenAI
- WebGPU
- Zero backend infrastructure
Proof of Concept
Watch the POC demonstration on video below
Presentation
Watch the presentation on ppt below
💡Final thoughts
A new phase where “AI apps” won’t necessarily mean “cloud services”
- 🔐 software that runs locally — and thinks locally


Use the share button below if you liked it.
It makes me smile, when I see it.